Repoformer
Repoformer 这篇论文的 motivation 是:不是每次 repository-level code completion 都该检索,所以要让模型自己判断要不要检索。
如果只记一句话:Repoformer 是一种 self-selective RAG 框架。它把“是否需要跨文件上下文”做成代码模型自己的一个预测行为:模型看到当前文件的 left/right context 后,先预测一个特殊 token <cc>;如果 <cc> 概率足够高,就触发 cross-file retrieval,否则直接做 fill-in-the-middle completion。
Repoformer 的贡献是发现“检索不是总有用”,于是把 always-retrieve 改成 selective-retrieve。这个判断很重要,因为它把 repository-level RAG 从“默认塞上下文”推进到了“先判断上下文是否值得塞”。但它本质上解决的是 retrieval gating,不是上下文压缩,也不是 code agent 在满上下文后的记忆/证据管理问题。
基本信息
| 字段 | 内容 |
|---|---|
| 来源 | arXiv:2403.10059v2 |
| 标题 | Repoformer: Selective Retrieval for Repository-Level Code Completion |
| 作者/机构 | Di Wu, Wasi Uddin Ahmad, Dejiao Zhang, Murali Krishna Ramanathan, Xiaofei Ma / UCLA, AWS AI Labs |
| 会议 | ICML 2024 |
| 日期 | 2024-06-04 |
| 链接 | https://arxiv.org/abs/2403.10059 |
| 项目/Benchmark | https://repoformer.github.io/ |
| 相关 topic | Context Compression |
研究问题
仓库级代码补全的输入可以写成:
其中:
| 符号 | 含义 |
|---|---|
X_l | 目标 completion 左侧的当前文件上下文 |
X_r | 目标 completion 右侧的当前文件上下文 |
Y | 需要生成的真实代码片段 |
F | 仓库中其他文件集合 |
CC | 从 F 中检索出的 cross-file contexts |
传统 repository-level RAG 会把当前文件上下文作为 query,从仓库其他文件里检索相关代码片段 CC,然后把 X_l、X_r 和 CC 一起喂给代码模型生成 Y。
论文挑战的是一个朴素但很常见的假设:
Should we always perform retrieval augmentation?
作者的结论是否定的。原因有两个:
- 很多补全任务只靠当前文件上下文就够了,跨文件检索没有边际收益。
- 检索结果经常带来无关或错误信号,会让模型生成质量下降。
所以问题从“如何检索更多上下文”变成了:
给定当前补全位置,模型能不能判断 retrieval 是否值得触发?关键发现:检索经常没用,甚至有害
论文先做了一个很重要的 empirical observation:在 RepoEval 的 API/function completion 上,对常见代码模型来说,retrieved cross-file contexts 的帮助很稀疏。
大致现象是:
| 情况 | 比例/趋势 |
|---|---|
| retrieval 提升生成质量 | 约 20% 或更少 |
| retrieval 对结果几乎无影响 | 超过 60% |
| retrieval 让结果变差 | 约 20% |
这个趋势在 CodeGen-Mono、StarCoder、StarCoderBase 等不同模型和不同任务粒度上都存在。
这说明 always-retrieve 有两个问题:
- 效率问题:每次都检索会增加 latency,尤其 dense retrieval、大仓库和 iterative RAG 更明显。
- 鲁棒性问题:retrieved snippets 可能和当前 completion 表面相似但语义不相关,模型会被噪声带偏。
因此,Repoformer 的目标不是替换 RAG,而是让 RAG 变成按需触发的能力。
方法总览:Self-Selective RAG
Repoformer 把普通 fill-in-the-middle completion 扩展成一个两分支流程:
flowchart LR A["Current file<br/>left context X_l + right context X_r"] --> B["Repoformer self-assessment"] B -->|predict empty / low p(<cc>)| C["No retrieval"] C --> D["FIM code completion"] B -->|predict <cc>| E["Cross-file retrieval"] E --> F["Retrieved contexts CC"] F --> G["RAG code completion"]
实现上,模型看到:
<fim_prefix> X_l <fim_suffix> X_r <eof>然后在 <eof> 后进行 self-evaluation:
- 如果
<cc>的概率超过阈值T,就触发检索; - 如果没有触发检索,就直接进入
<fim_middle>生成 completion; - 如果触发检索,就把
CC加入 prompt,再进入<fim_middle>生成 completion。
这个设计有两个好处:
- 决策开销低:只需要一次模型前向预测
<cc>概率,不需要 trial generation 或 trial retrieval。 - 和 FIM 预训练兼容:StarCoder 本身学过 fill-in-the-middle,Repoformer 只是把 retrieval decision 插进 FIM 流程。
自监督标签:看 retrieval 是否真的提升结果
Repoformer 最关键的是 label construction。它没有人工标注“这题需不需要检索”,而是通过模拟 RAG 自动构造标签。
训练数据构造大致分三步:
- 从 The Stack 中筛选 permissively licensed Python 仓库。
- 在仓库中采样不同粒度的 target completion,包括 code chunks 和 function bodies。
- 对每个样本分别评估:
- 只用
X_l, X_r的 completion; - 加上 retrieved
CC的 completion。
- 只用
如果带 CC 后的 Edit Similarity 相比不带 CC 提升超过阈值 T,就把这个样本标为 retrieval-positive,也就是“应该触发 <cc>”。
直觉上,标签不是来自“retrieved snippet 看起来是否相似”,而是来自:
retrieval 是否真的改善了模型最终补全结果这点对 context pruning 很重要。因为上下文选择的目标不应该是“相关性看起来高”,而应该是“对下游任务有边际贡献”。
训练目标
Repoformer 同时训练两个能力:
- self-assessment:判断是否需要 retrieval;
- robust generation:在有或没有 retrieved context 的情况下都能补全代码。
论文使用两个 loss:
Leval
Leval 是 <eof> 后预测 <cc> 的 cross-entropy loss:
它负责让模型学会判断当前 completion 是否能从 cross-file context 中获益。
Lgen
Lgen 是正常代码生成 loss。根据标签不同,模型要么在无检索条件下生成:
要么在带检索条件下生成:
最终目标是:
这使得 Repoformer 不只是一个 retrieval classifier,也仍然是一个代码生成模型。
检索设置
主实验里,Repoformer 沿用 RepoCoder/RepoEval 一类工作的 repository-level RAG 设置:
| 阶段 | 做法 |
|---|---|
| Indexing | 把仓库其他文件按 sliding window 切成代码块 |
| Query formation | 用 X_l 末尾若干行作为 query |
| Retrieval | 默认用 Jaccard similarity,取 top-k snippets |
| Generation | 把 retrieved snippets 作为注释拼进 prompt |
主要超参:
| 参数 | 值 |
|---|---|
| line/API/chunk completion chunk size | 20 行 |
| function completion chunk size | 50 行 |
| top-k retrieved chunks | 10 |
| left context | 1024 tokens |
| right context | 512 tokens |
| cross-file context | 512 tokens |
| line/API/chunk max generation | 50 tokens |
| function max generation | 256 tokens |
一个值得注意的点是:论文强调 X_r 很重要。也就是说,它不是只做 left-to-right completion,而是强烈利用 right context 做 infilling。Appendix B 显示,不管有没有 cross-file context,加入 right context 都能显著提升代码补全效果。
实验设置
模型基于 StarCoderBase 训练,得到:
| 模型 | 规模 |
|---|---|
| Repoformer-1B | 1B |
| Repoformer-3B | 3B |
| Repoformer-7B | 7B |
| Repoformer-16B | 16B |
训练数据:
| 项 | 内容 |
|---|---|
| 仓库来源 | The Stack |
| 过滤后仓库 | 18k Python repositories |
| chunk completion 样本 | 240k |
| function completion 样本 | 120k |
| 训练 epoch | 2 |
| max sequence length | 2048 |
评测集包括:
| Benchmark | 任务 |
|---|---|
| RepoEval | line/API/function completion |
| CrossCodeEval | Python/Java/C#/TypeScript line completion |
| CrossCodeLongEval | 新构造的 chunk/function completion benchmark |
评估指标:
| 指标 | 含义 |
|---|---|
| EM | Exact Match |
| ES | Edit Similarity |
| UT | Unit test pass rate |
| %RAG | 触发 retrieval 的样本比例 |
| SU | 相比 always-retrieve 的 speedup |
主要结果
准确率
Repoformer 的 selective retrieval 在多数任务上都优于同规模 StarCoderBase 的 no-retrieval 和 always-retrieval。
几个关键结论:
- Repoformer-3B 在多项任务上超过 StarCoderBase-7B。
- Repoformer-3B 的效果可以接近或超过 16B StarCoder 的 always-retrieval baseline。
- Repoformer-16B 在 RepoEval 和 CrossCodeLongEval 上达到新的 state-of-the-art。
- threshold selection 通常比 greedy selection 准确率更好。
以论文 Table 2 的整体趋势看,selective retrieval 不是牺牲准确率换速度;相反,它经常因为避开 harmful retrieval 而提升准确率。
延迟
Repoformer 的 latency 收益来自:当模型判断不需要 retrieval 时,可以完全跳过 retrieval 开销。
论文在 online serving 设定里把流程拆成三个并行过程:
| 过程 | 含义 |
|---|---|
P1 | Repoformer 判断是否需要 retrieval |
P2 | 不带 CC 直接生成 |
P3 | 检索 CC 后生成 |
如果 P1 判断不需要 retrieval,就等 P2;如果需要 retrieval,就等 P3。
结果显示:
- greedy selection 可以带来更大 speedup,但可能轻微损失 ES;
- threshold selection 通常同时提升 ES 和降低 latency;
- 在 dense retrieval 或大仓库设置下,跳过 retrieval 的收益更大,最高可带来约 70% speedup。
作为 plug-and-play retrieval policy
Repoformer 也可以不做最终生成,只作为一个小 policy model,为更大的模型决定要不要检索。
论文用 Repoformer-1B 给 StarCoderBase、CodeGen25、CodeLlama、ChatGPT 等模型做 selective RAG policy,发现通常可以:
- 降低约 20%-30% latency;
- 同时略微提升 ES。
这说明 Repoformer 学到的不是完全绑定自身生成器的技巧,而是一种相对可迁移的 retrieval decision ability。
为什么有效
论文的分析部分说明 Repoformer 的收益来自两个方面。
1. 准确 abstain
当 Repoformer 选择不检索时,大多数样本属于两类:
- 模型本来不用 retrieval 就能答对;
- retrieval 也救不了这个样本。
换句话说,它很少跳过真正有帮助的 retrieval。论文报告 abstention precision 在大多数任务上超过 0.8。
2. 对 retrieved context 更鲁棒
在 Repoformer 选择触发 retrieval 的样本上,它比 StarCoderBase 更能从 CC 中获得收益,并且更少因为 CC 而性能下降。
这说明训练中的 Lgen 不只是让模型学会补全,也让模型学会了:
有用的 retrieved context 要用;
没用或噪声 context 要尽量忽略。这对 coding agent 很重要,因为真实工具返回的上下文很少是完全干净的。
Ablation
论文比较了几个替代设计:
| 变体 | 含义 | 结果 |
|---|---|---|
| A1 | 把 Leval 和 Lgen 合成一个普通 CE loss | RAG 能力还行,但几乎总是预测要检索,失去 selective ability |
| A2 | 去掉 self-evaluation loss | 生成能力可保留,但没有检索决策能力 |
| A3 | 只训练 FIM,不训练 CC | in-file completion 还行,但 RAG performance 变差 |
| A4 | 把 CC 放在 <fim_middle> 后 | function completion 明显变差,可能破坏 FIM 语义 |
这说明 Repoformer 的结构不是随便加一个特殊 token 就够了。Leval 必须被明确监督,CC 的位置也要和 FIM 预训练语义兼容。
和 RepoCoder 的关系
RepoCoder 和 Repoformer 都是 repository-level code completion 的 RAG 方法,但它们解决的问题不同。
| 维度 | RepoCoder | Repoformer |
|---|---|---|
| 核心问题 | 当前 unfinished code 不是好 query | retrieval 不总是有用 |
| 关键机制 | iterative retrieval-generation | self-selective retrieval |
| 使用 generation 的方式 | 用 draft completion 改进下一轮 retrieval query | 用模型自评决定是否触发 retrieval |
| 主要收益 | 检索更贴近目标 completion | 降低噪声和 latency |
| 对 context pruning 的启发 | 生成中间结果可作为检索意图 | 上下文进入前应做价值判断 |
可以把二者合起来理解:
RepoCoder: 如果要检索,怎样构造更好的 query?
Repoformer: 当前这一步到底要不要检索?在 coding agent 里,这两个问题都存在。一个强 agent 不仅要会搜,还要知道什么时候不搜、搜什么、搜完哪些内容值得进上下文。
和 context pruning 的关系
Repoformer 严格来说不是已有上下文的 pruning 方法,而是 retrieval-time context admission control。
它对应的是上下文生命周期中的更早阶段:
candidate context -> decide whether to retrieve/admit -> prompt context -> generation而不是:
long prompt already built -> compress/prune -> shorter prompt但它对 coding agent context pruning 的启发很强:
-
上下文不是越多越好 代码模型会被无关 retrieved snippets 干扰,特别是表面相似但语义不匹配的片段。
-
pruning policy 应该以任务收益为监督信号 相似度、BM25 分数、embedding 分数都只是 proxy。更好的标签是“加入这段上下文后最终任务结果是否改善”。
-
pruner / retriever 要和 reader model 对齐 同一段
CC对不同模型的边际价值不同。Repoformer 的标签是相对于一个具体代码模型构造的,这比纯相关性标注更贴近实际生成效果。 -
选择性上下文可以同时提升质量和效率 selective retrieval 并不是单纯省 token;它还可能通过避开 harmful context 提升准确率。
-
agent 场景可以扩展成多动作 policy Repoformer 只有 retrieve / no retrieve 两个动作。对 coding agent,可以扩展成:
- 不读;
- 读当前文件;
- 搜 symbol;
- 搜调用点;
- 搜测试;
- 读最近 traceback;
- 读 git blame / history;
- 保留或丢弃某段 tool output。
局限
1. 主要是 completion,不是完整 coding agent
Repoformer 评估的是 repository-level code completion,包括 line/API/function/chunk completion。它没有评估完整的 issue solving trajectory,例如 SWE-Bench 上的多轮搜索、修改、运行测试和再修改。
所以它证明的是:
selective retrieval improves repo-level code completion还不是:
selective retrieval/pruning improves end-to-end coding agent solve rate2. 标签依赖 Edit Similarity
训练标签用 ES 判断 retrieval 是否有帮助。ES 对 line/API/chunk completion 比较方便,但对 function-level semantic correctness 不够理想。
论文也观察到 function completion 上的 calibration 更弱。更好的方向可能是用 unit tests、static analysis、type checking 或 execution feedback 构造 retrieval-benefit label。
3. retrieval action 太粗
Repoformer 的动作空间只有:
retrieve CC / do not retrieve CC但真实 coding agent 的上下文选择更复杂:不同工具、不同文件粒度、不同 symbol、不同测试输出都可能需要不同 admission policy。
4. 仓库个性化不足
论文使用统一 selective policy,但不同仓库的 RAG 友好程度可能不同。有些仓库高度重复、模式明显,retrieval 很有用;有些仓库模块边界清晰、重复少,retrieval 价值较低。
未来可以做 repository-personalized retrieval policy。
我的理解与判断
Repoformer 的价值在于它把 repository-level RAG 里的一个默认动作显式问题化了:检索不是总有用,所以不能默认塞上下文。
它的贡献不是“压缩已经进入 prompt 的长上下文”,而是把 always-retrieve 改成 selective-retrieve:先让模型判断当前 completion 是否需要 cross-file context,再决定是否触发 retrieval。这一步属于 retrieval gating 或 context admission control,比 compression 发生得更早。
因此,Repoformer 可以作为 agent compression 脉络里的早期前置思想,但边界要说清楚:它不是上下文压缩方法,也没有解决 code agent 在满上下文后如何维护记忆、保留证据、丢弃旧 observation 的问题。真实 agent 中的 grep、cat、test output、traceback、retrieved snippets 仍然需要后续的 evidence management 和 tool-output pruning。
更好的范式可能是:
before-read / before-retrieve:
decide whether this context source is worth querying
after-read / after-retrieve:
prune or extract the useful parts
before-generation:
decide whether retained context is enough or needs more evidenceRepoformer 主要覆盖第一层:before-retrieve 的选择性触发。SWE-Pruner、Squeez 这类方法更偏第二层:tool output 已经拿到后,怎么裁剪掉无关行或无关片段。两类工作要区分开看,合起来才更像一个完整的 coding agent context management stack。
总结
Repoformer 是一篇很适合作为 coding agent context pruning 背景阅读的论文,但它本身更准确地说是 retrieval gating,而不是 context compression。它的主要贡献不是提出更强的 retriever,而是证明了一个关键原则:retrieval augmentation 应该是 conditional 的,而不是默认发生的。
它通过 self-supervised labeling 和 multi-task fine-tuning,让代码模型同时学会:
- 判断跨文件上下文是否可能提升当前补全;
- 在需要时利用 retrieved context;
- 在不需要时跳过 retrieval;
- 对 noisy retrieved context 更鲁棒。
从应用角度看,它给 coding agent 的启发是:上下文管理应该尽早发生,且应以最终任务收益为目标。对 agent 来说,未来更值得做的不是单一 retrieve/no-retrieve,而是把工具选择、上下文准入、span pruning、证据充分性判断统一成一个动态 policy。
论文图表摘录
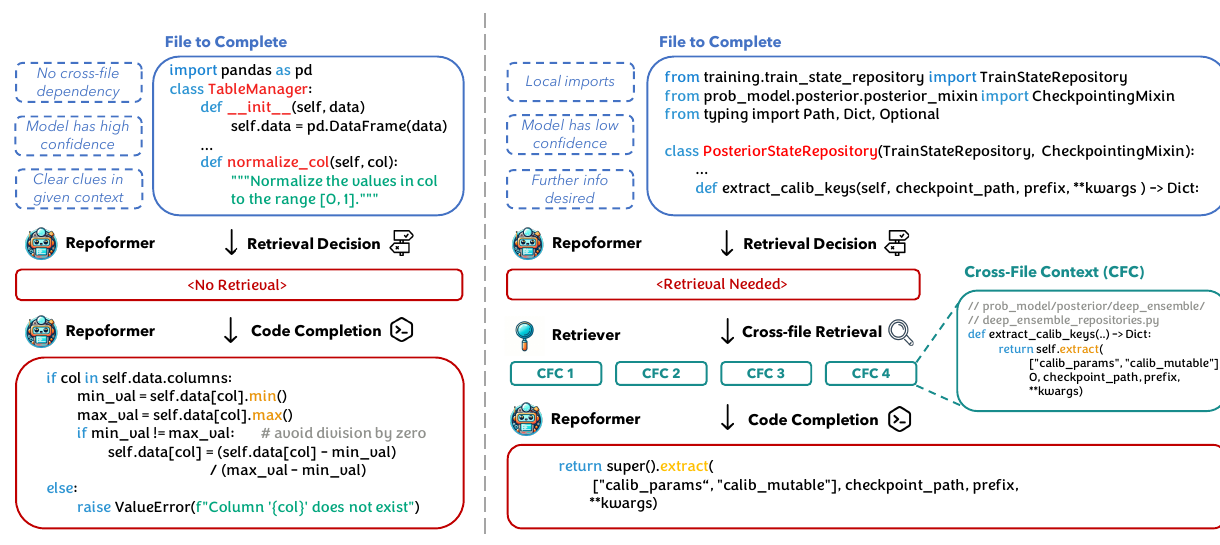
Repoformer Figure 1: selective RAG framework overview
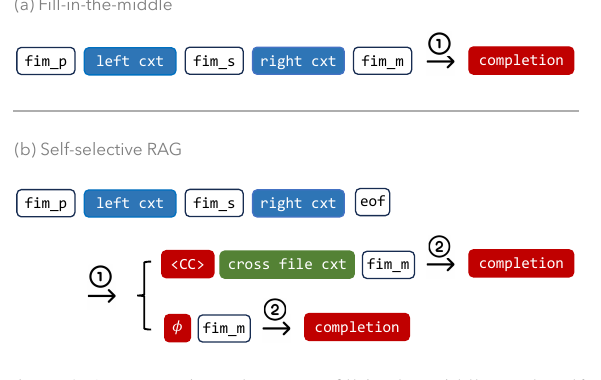
Repoformer Figure 2: self-selective RAG 与 FIM 对比
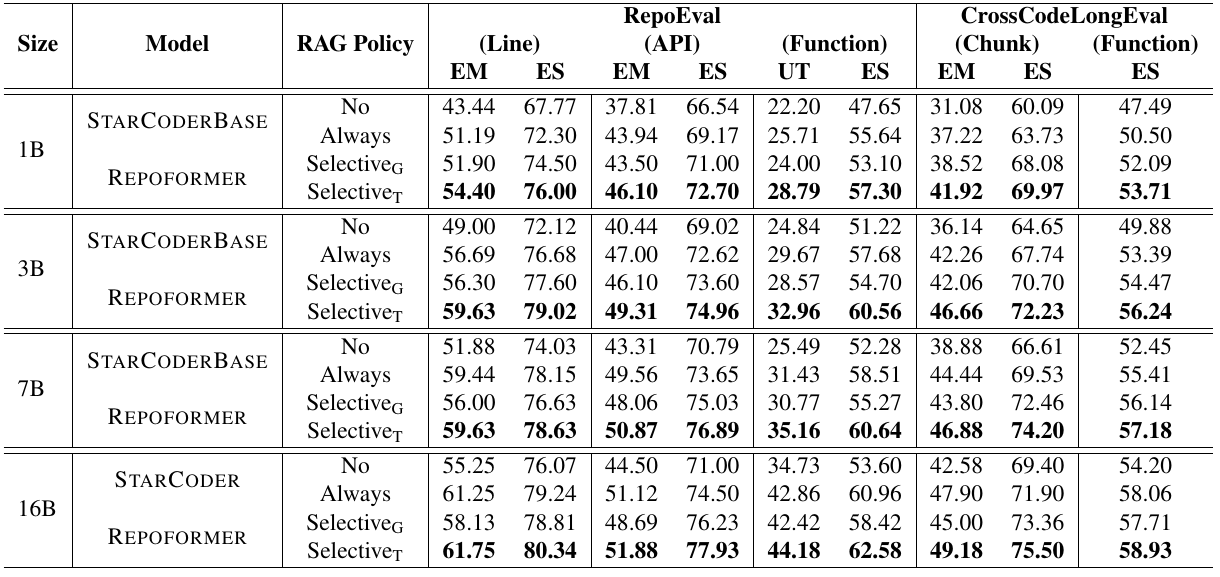
Repoformer Table 2: RepoEval / CrossCodeLongEval 主结果
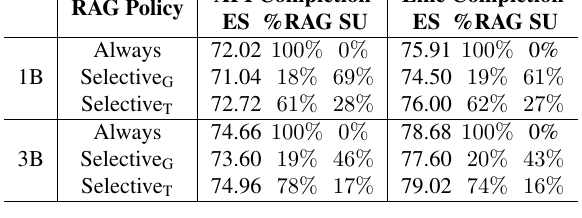
Repoformer Table 3: selective retrieval ablation
相关知识链接
References
2403.10059v2.pdf- https://arxiv.org/abs/2403.10059
- https://repoformer.github.io/