基本信息
- Title: LongCodeZip: Compress Long Context for Code Language Models
- Authors: Yuling Shi, Yichun Qian, Hongyu Zhang, Beijun Shen, Xiaodong Gu
- Institutions: Shanghai Jiao Tong University, Stanford University, Chongqing University
- Date: 2025-10-01
- Venue: ASE 2025
- Code:
https://github.com/YerbaPage/LongCodeZip - Related topic notes: Context Compression, Retrieval, Chunking
这篇论文提出 LongCodeZip,一个面向 code LLM 的 training-free、model-agnostic、plug-and-play 长代码上下文压缩框架。它的 motivation 和 CodeRAG 一样,也是在说:相关不一定好用。长代码上下文里,embedding / BM25 / RAG 召回的片段可能和 query 看起来相关,但真正要保留的是“加入后能让模型更理解当前 instruction / target”的片段。
它仍然使用 PPL 作为信号,但不是直接看某段代码自己的困惑度,而是看 加入这段 context 后,instruction 的 PPL 减少了多少。这个差值更有含义:如果给定某个代码片段后,模型生成/解释当前 instruction 更容易,说明这个片段对任务更可能是有用上下文。
论文的关键设计是两阶段压缩:先按函数或类边界切分代码,计算每个函数级 chunk 对 instruction 的 AMI,按分数排序,并在粗粒度预算内保留最相关函数;再对已保留的大函数继续切成语义 block,根据函数重要性分配 token budget,用 0/1 knapsack 选择最有价值的 block。相比普通文本压缩或仅靠 embedding 相似度的 RAG,LongCodeZip 更强调代码结构、跨函数依赖和任务指令之间的关系。
研究问题
长上下文代码生成常见于 repository-level code completion、module summarization 和 code question answering。虽然现代 code LLM 的上下文窗口不断变长,但实际使用仍然有三个瓶颈:
- 代码上下文越长,输入 token 成本和生成延迟越高;
- 相关代码可能散落在不同函数、类或文件中,长输入会稀释模型注意力;
- 即使上下文窗口足够大,模型也可能忽略中间位置或低表面相似度但高依赖价值的代码。
普通 RAG 可以缩短上下文,但常用 embedding similarity 更擅长捕捉词面或语义相似,而不一定能捕捉代码里的隐式依赖。论文用一个例子说明:补全 train_model(model, dataloader, config: Config) 时,真正关键的 Config 类可能与目标函数没有强词面重叠,但它决定了 lr、epochs、weight_decay 等参数的来源。
因此论文要回答的问题是:能否设计一种不训练新模型、不绑定特定生成模型、同时理解代码结构和任务指令的长代码上下文压缩方法?
核心主张
LongCodeZip 的核心主张是:代码上下文压缩不应该只问“这个片段和 query 像不像”,而应该问“这个片段加入 context 后,是否真的降低了模型对当前 instruction 的不确定性”。换句话说,相关不一定好用;能降低 instruction PPL 的 context 才更像好用上下文。
论文使用 approximated mutual information, AMI,衡量候选代码片段 对任务指令 的帮助:
其中:
- 是没有候选代码时生成 instruction 的困惑度;
- 是加入候选代码 作为 context 后生成 instruction 的条件困惑度;
- AMI 越高,说明该代码片段加入后越能降低模型对 instruction 的困惑度,越可能是任务真正好用的上下文。
这个信号比纯 embedding similarity 更贴近生成模型本身的条件预测行为,也更适合捕捉代码中的非词面依赖。它仍然是 PPL proxy,但比“代码片段本身 PPL 高不高”更任务相关,因为它测的是 context 对 instruction 的边际帮助。
方法与机制
两阶段压缩流程
LongCodeZip 的输入包括长代码上下文、任务指令和 token budget。输出是满足预算的压缩上下文 。
流程可以拆成两层:
- Coarse-grained compression:按函数或类边界切分代码,计算每个函数级 chunk 对 instruction 的 AMI,按分数排序,并在粗粒度预算内保留最相关/最好用的函数。
- Fine-grained compression:对已保留的大函数继续切成语义 block,根据函数重要性分配 token budget,再用 0/1 knapsack 选择最有价值的 block。
这种设计利用了代码的天然结构。函数级选择能快速过滤大量无关内容;函数内 block 选择则避免“保留一个相关函数就必须保留完整函数”的浪费。
函数级 instruction-aware ranking
粗粒度阶段先按函数或类边界切分代码。这样做有两个好处:
- 函数通常是相对自包含的逻辑单元,比任意 token 或固定窗口更不容易破坏语法结构;
- 对 repository-level 任务来说,关键上下文常常以函数、类、配置对象或工具函数形式出现。
每个 chunk 都用 AMI 打分。实现上,压缩模型计算 instruction 在“无该 chunk”和“给定该 chunk”两种条件下的 perplexity 差值。分数高的函数优先保留,因为它们对 instruction 的不确定性降低更明显。这个 ranking 不是在问“函数和 query 词面像不像”,而是在问“这个函数作为 context 后,instruction 是否更容易被模型预测/解释”。
未保留的 chunk 会被替换成 placeholder,例如注释或省略标记,用于保留全局代码布局。这一点对代码场景有价值,因为完全删除上下文可能让模型失去文件结构、类结构或模块位置感。
函数内 perplexity block detection
细粒度阶段的难点是:不能像普通文本压缩那样随意删 token,否则很容易破坏代码语法、缩进和依赖。
LongCodeZip 把代码行作为最小单元,计算逐行 perplexity,并观察局部突增。当某一行的 perplexity 明显高于邻近行且超过全局标准差阈值时,将其视为新 block 的边界。直觉是:在一个语义连贯的 block 内,随着前文积累,后续行更容易预测;当进入新的逻辑块、控制流分支或功能段落时,困惑度会突然上升。
这比简单按空行或固定行数切块更贴近代码语义,但仍然是启发式方法,不保证与 AST 或程序依赖图完全一致。
Adaptive budget allocation
被粗粒度阶段选中的函数重要性不同,所以细粒度压缩不使用统一保留比例。LongCodeZip 先把函数 AMI 做 min-max normalization,然后根据重要性调整每个大函数的 retention ratio:
其中:
- 是大函数的基础保留比例;
- 控制重要性对预算分配的影响;
- AMI 更高的函数会获得更多 token budget;
- 少于 5 行的小函数默认完整保留。
这个机制解决了一个常见问题:如果所有函数都按同一比例裁剪,真正关键的长函数可能被删掉太多细节,而次要函数却保留了不必要内容。
0/1 knapsack block selection
在每个已保留的大函数内部,LongCodeZip 把 block selection 建模成 0/1 knapsack:
- item 是候选 block;
- weight 是 block token 数;
- value 是 block 的 normalized AMI;
- capacity 是该函数分到的 token budget。
目标是在该函数分到的 token budget 内最大化保留 block 的总价值。论文使用动态规划求解,并允许把用户指定的 preserved set 强制保留。
这个形式把“压缩”从简单截断转成了预算约束下的信息密度优化。
实验与证据
论文覆盖三类长代码任务:
| Task | Dataset | Examples | Avg. context length | Metric |
|---|---|---|---|---|
| Code completion | Long Code Completion | 500 | 9,328.2 tokens | EM, Edit Similarity |
| Code summarization | Long Module Summarization | 139 | 10,809.6 tokens | GPT-4o-mini CompScore |
| Code QA | RepoQA | 600 | 11,524.6 tokens | BLEU-based retrieval accuracy |
对照方法包括 no compression、no context、random token/line、RAG sliding window、RAG function chunking、LLMLingua 系列、DietCode 和 SlimCode。模型覆盖 DeepSeek-Coder-6.7B、Qwen2.5-Coder-7B、Seed-Coder-8B,以及 GPT-4o 和 Claude-3.7-Sonnet。
主要结果:
- 在 Long Code Completion 上,LongCodeZip 在三个开源模型上都优于 RAG 和压缩 baseline。例如 Qwen2.5-Coder-7B 上达到 57.55 ES / 32.40 EM,压缩比 4.3x;RAG function chunking 为 52.79 ES / 26.00 EM,压缩比 3.1x。
- 在 Long Module Summarization 上,LongCodeZip 在 DeepSeek-Coder、Qwen2.5-Coder、Seed-Coder 上分别达到 28.01、56.47、55.07 CompScore,是压缩方法中最强或最接近 no compression 的方法。
- 在 RepoQA 上,LongCodeZip 对结构完整性的优势更明显。例如 Qwen2.5-Coder-7B 上 average accuracy 达到 87.2,甚至略高于 no compression 的 86.0,同时压缩比 4.5x。
- 在闭源模型上,LongCodeZip 也接近或超过 no compression。Claude-3.7-Sonnet 上 code completion 为 66.27 ES,对比 no compression 66.24 ES;RepoQA 为 88.9 average accuracy,压缩比 5.1x。
消融实验显示,粗粒度 AMI ranking 是最关键组件。Qwen2.5-Coder-7B 的 Long Code Completion 中,完整 LongCodeZip 为 57.55 ES;改成 similarity-based ranking 降到 49.66,random ranking 降到 39.76。细粒度组件也有增益:去掉 adaptive budget、改成 line chunking 或 random line selection 都会降低 ES。
效率实验中,LongCodeZip 在 Qwen2.5-Coder-7B 上引入约 2.58 秒压缩开销,但把生成时间从 15.70 秒降到 6.59 秒,输入 token 成本降低约 77%,同时保持最高 ES/EM。跨模型实验还显示,用 Qwen2.5-Coder-0.5B 作为 compressor 也能得到接近 7B compressor 的效果,说明压缩模型可以轻量化。
关键结论
LongCodeZip 的稳定价值不在于某个具体 benchmark 数字,而在于提出了三个可复用原则:
- 长代码上下文压缩要保留代码结构边界,函数、类和 block 通常比固定 token 窗口更适合作为压缩单元;
- 任务相关性不等于 embedding similarity,条件困惑度或 AMI 能更直接衡量“候选上下文是否帮助模型理解当前任务”;
- 压缩应当是预算分配问题,高价值函数应获得更多细节预算,低价值函数可以只保留结构占位。
对于 code agent、repository-level completion 和代码问答系统,这意味着 RAG 检索后还可以继续做代码感知压缩:先召回可能相关的文件或函数,再用 instruction-aware compression 在 token budget 内保留高信息密度上下文。
我的评价是:LongCodeZip 的优点在于 AMI 筛选能够有效估计 context 的信息增益,比纯相似度更接近“这个片段加入后是否真的有帮助”。但它仍然没有解决 compressor 和 generator 之间的 gap:AMI 是由 compressor model 计算出来的,压缩器认为能降低 instruction PPL 的片段,不一定就是最终 generator 最会用、最能生成正确答案的片段。
局限与疑问
- AMI ranking 需要运行压缩模型计算条件困惑度,因此比简单 embedding retrieval 有额外推理开销;虽然论文展示总体 generation latency 下降,但在极低成本或极低延迟场景中仍需权衡。
- AMI 衡量的是 compressor model 眼中的信息增益,不等于 generator 的真实使用收益;compressor-generator gap 仍然存在。
- 函数级切分依赖代码结构,面对脚本式代码、跨语言混合文件、动态生成代码或宏系统时,函数边界可能不稳定。
- Perplexity block detection 是启发式语义切分,不等价于 AST、CFG、data-flow 或 program dependence graph。
- 如果任务指令本身含糊,或者原始上下文缺失真正相关代码,LongCodeZip 也无法可靠选出有用片段。
- Summarization 使用 LLM-as-Judge 评估,尽管论文采用顺序反转来缓解 bias,但仍不是人工评审的完全替代。
论文图表摘录

LongCodeZip Table I: evaluation datasets
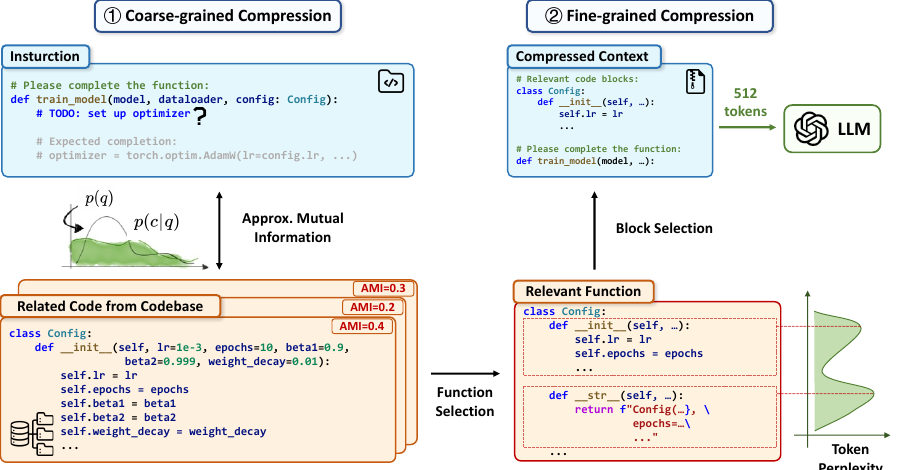
LongCodeZip Figure 2: coarse-to-fine compression framework

LongCodeZip Algorithm 2: knapsack block selection
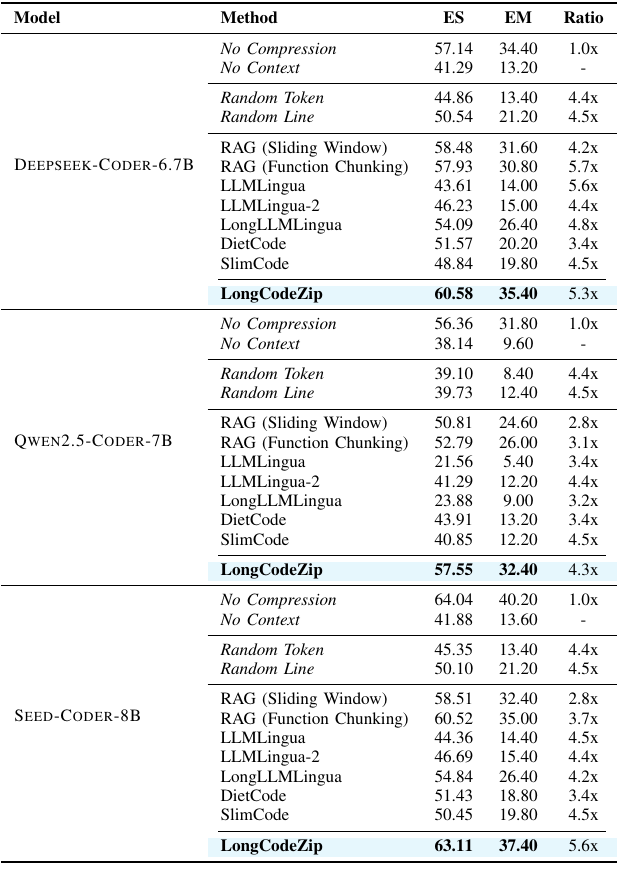
LongCodeZip Table II: Long Code Completion 结果
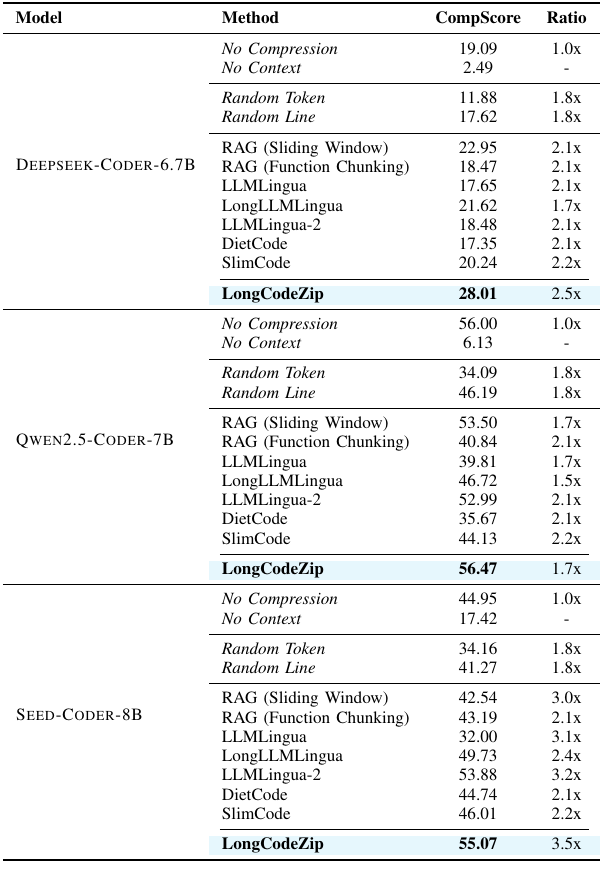
LongCodeZip Table III: Long Module Summarization 结果
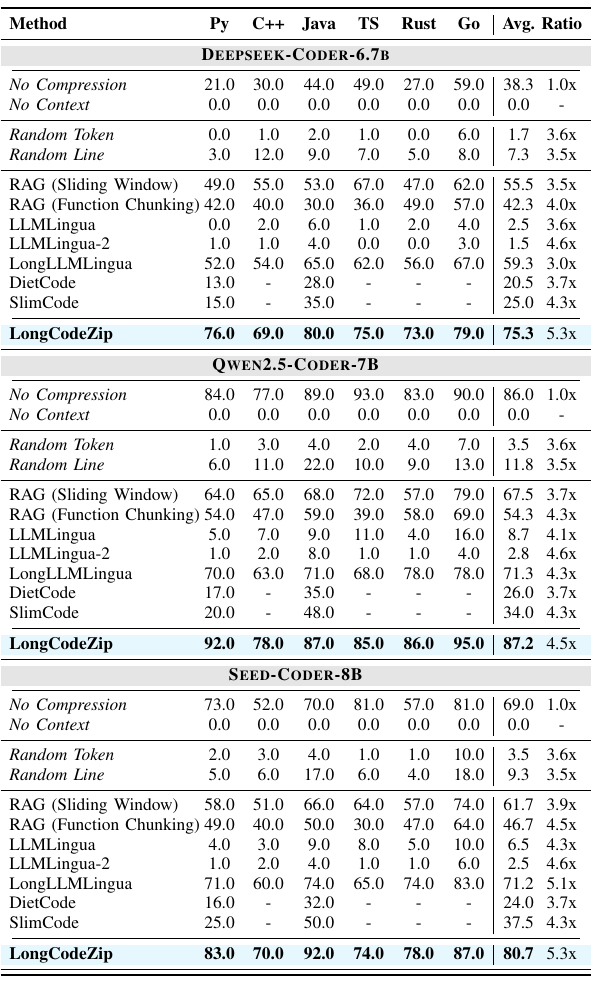
LongCodeZip Table IV: RepoQA 结果