Squeez
论文定位
Squeez 这篇论文讨论的是 coding agent 中一个很具体的压缩问题:当 agent 调用工具后拿到一段很长的 tool observation,如何根据当前 query 抽出下一步最值得看的最小证据块。
我理解这篇论文的主要贡献是:它把 coding agent 的复杂多轮上下文压缩问题,简化成一个单轮、可监督、可评测的 evidence extraction 任务。
基本信息
| 字段 | 内容 |
|---|---|
| 来源 | arXiv:2604.04979v1 |
| 作者/机构 | Adam Kovacs, KR Labs |
| 日期 | 2026-04-04 |
| 链接/代码 | https://arxiv.org/abs/2604.04979, https://github.com/KRLabsOrg/squeez |
| 相关 topic | Context Compression |
任务定义
论文把输入形式化为:
其中:
q是一个简短的、面向任务的抽取查询;o是一次原始工具观测结果,也就是 raw tool observation。
输出是在 o 上的一个或多个连续片段集合:
这里 (s_i, e_i) 表示第 i 个证据块的起始行和结束行。每个证据块内部是连续的,但可以有多个证据块,所以相关信息不一定只能来自工具输出中的同一处。
从任务形式看,Squeez 的目标不是生成新答案,而是从原始 observation 中保留 verbatim evidence。这个设定对 coding agent 很重要,因为 traceback、错误行、commit、配置项、exit code 这类信息一旦被摘要改写,就可能丢掉关键细节。
数据集构造
Squeez 的 benchmark 来自三类样本:
| 来源 | 数量 | 含义 |
|---|---|---|
| SWE-bench derived | 10,713 raw observations | 在 SWE-bench 仓库快照上执行 14 种工具得到的原始观测 |
| Synthetic positives | 2,039 raw observations | 用 openai/gpt-oss-120b 生成的多生态工具输出 |
| Synthetic negatives | 575 released rows | 将不匹配的 query 和 tool output 配对,正确答案为空 |
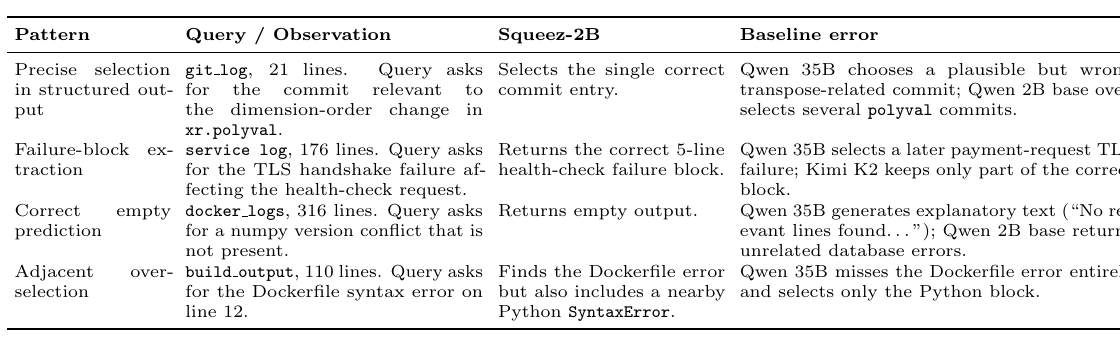
SWE-bench derived 部分覆盖 file read、grep、git log、git blame、test runner、linter、type checker、pip install、curl 等工具。这些输出比较接近 coding agent 在真实修复任务里会看到的 observation。
Synthetic positives 主要用于弥补 SWE-bench 的 Python 偏置,覆盖 TypeScript、Go、Rust、Java、Docker、Terraform、Kubernetes 以及相关构建或部署工作流。
我觉得 explicit negative examples 是一个很关键的设计。它让模型学习:当 query 要找的证据不在当前 tool output 里时,正确行为是返回空结果,而不是硬选一段看起来相关的内容。这一点很贴近真实 agent 场景,因为 agent 经常会在错误的工具输出里寻找某个假设证据。
数据集形态
一条样本大致可以理解为:
query + raw tool output -> gold spans其中 gold spans 记录哪些行是标准证据。benchmark 里保存的是原始工具输出上的 span 坐标,方便按行评测;训练生成式模型时,则把这些 gold span 对应的原文行展开,包在 <relevant lines> 标签中,作为模型的生成目标。
也就是说:
输入:
query + raw tool output
标签:
哪些行是 gold evidence
训练目标:
把这些行原样输出到 <relevant lines>...</relevant lines> 里这个设计让任务同时具备两种性质:从训练角度看,它是生成式抽取;从评测角度看,它仍然可以回到行级坐标,计算 recall、F1 和 compression。
模型与训练
Squeez 使用 Qwen 3.5 2B 作为 backbone,并用 LoRA 进行微调。模型输入是 focused query 和 raw tool output,输出是被 <relevant lines> 包裹的逐字抽取文本。
作者选择 2B 模型的理由不是追求最强 zero-shot reasoning,而是让 pruner 成为一个低成本的前处理模块。真正负责规划、搜索和修 bug 的仍然是主 agent 模型;Squeez 只需要学习一个窄任务:从当前 observation 里抽出下一步相关证据。
部署上,论文提到 LoRA adapter 会 merge 回 base model,然后通过 vLLM 服务;也可以作为 CLI filter 消费 piped tool output。这说明它的目标形态是嵌入 Codex、Claude Code 这类已有 coding agent,而不是替换 agent 本身。
评估指标
论文主要看 recall、F1 和 compression,尤其强调高压缩率下的 recall。这个选择是合理的:在 coding agent 场景里,漏掉 traceback 关键行、错误 commit、OOMKilled reason 或 assertion message,通常比多保留几行附近上下文更严重。
换句话说,tool-output pruning 的核心不是把文本压得越短越好,而是在强压缩下尽量不漏掉关键证据。
实验结果
论文在 618 条人工清洗后的 held-out test examples 上评估。主要结果如下:
| Model | Precision | Recall | Strict F1 | Exact | F1 | Compression |
|---|---|---|---|---|---|---|
| Squeez-2B | 0.80 | 0.86 | 0.79 | 0.49 | 0.80 | 0.92 |
| Qwen 3.5 35B A3B | 0.74 | 0.75 | 0.70 | 0.39 | 0.73 | 0.92 |
| Kimi K2 | 0.61 | 0.53 | 0.53 | 0.30 | 0.68 | 0.94 |
| Qwen 3.5 2B base | 0.42 | 0.53 | 0.41 | 0.19 | 0.55 | 0.82 |
| BM25 (10%) | 0.13 | 0.22 | 0.13 | 0.01 | 0.23 | 0.90 |
| First-N (10%) | 0.07 | 0.14 | 0.08 | 0.02 | 0.16 | 0.91 |
| Random (10%) | 0.07 | 0.10 | 0.07 | 0.01 | 0.20 | 0.91 |
| Last-N (10%) | 0.05 | 0.05 | 0.04 | 0.01 | 0.14 | 0.91 |
最关键的结果是:Squeez-2B 在移除 92% input tokens 的情况下,达到 0.86 recall 和 0.80 F1。它比 Qwen 3.5 35B A3B 的 zero-shot recall 高 11 个点,也明显强于 BM25、First-N、Last-N 这些启发式 baseline。
这个结果说明,tool-output pruning 不是简单的“取前几行”或“按词匹配”问题。因为相关证据可能出现在输出的任意位置,而且是否相关取决于 query。一个小模型经过专门监督训练后,反而比更大的 zero-shot 模型更适合做这个窄任务。
不过这个实验结果也要放在任务边界里理解:它证明的是单次 observation 上的 evidence preservation,而不是完整 agent 任务的 solved rate 提升。
我的理解与判断
我觉得 Squeez 的价值在于,它把一个实际存在但很难直接评测的问题,拆成了一个更干净的单轮任务:
query + one tool output -> relevant spans这个任务定义让数据构造、训练和评测都变得清晰,也能很好地说明为什么普通 BM25、First-N、Last-N 这类方法不够用。真实 tool output 不是普通文档,它经常混合代码、日志、shell 输出、Git 历史、构建错误和部署状态。相关证据可能在开头、中间或结尾,也可能是某个很小的错误块。
但是,我也觉得这篇论文的主要局限就在于它是单轮次的。它没有评估完整的 coding agent trajectory:
agent 多轮搜索 / 阅读 / 执行 / 修改 -> 最终是否解决问题因此,Squeez 的结果更准确地说只能证明:在单次 tool-output pruning 任务上,小模型能够以较高 recall 保留相关证据,并显著压缩输入。它还不能直接证明加入真实 agent 后,一定能减少轮数、降低成本或提高 issue resolve rate。
和 SWE-Pruner 的关系
我更倾向于把 Squeez 理解成对 SWE-Pruner 这类小模型 observation pruner 的一种替代表述,而不是完整替代方案。
SWE-Pruner 更像是在 agent read tool 前后引入一个 goal-aware 的 line-level pruner,通过小模型对代码上下文做 retain / prune 判断。Squeez 则把这个任务改写成 query-conditioned generative span extraction:不再显式给每一行打分或分类,而是让模型直接生成 <relevant lines> 中应该保留的原文证据。
所以二者的区别可以概括为:
| 维度 | SWE-Pruner | Squeez |
|---|---|---|
| 任务形式 | Goal Hint + context → line-level retain/prune | query + tool output → relevant spans |
| 输出方式 | 行级打分或分类 | 生成式原文证据抽取 |
| 主要场景 | 更偏代码上下文剪枝 | 更偏 mixed-format tool output |
| 评测重点 | 更接近 agent 任务效果 | 单次 observation 的 recall/F1/compression |
从这个角度看,Squeez 更像是改进了小模型 pruner 的训练目标和输出方式,但它仍然停留在单轮 observation pruning 层面。
总结
Squeez 是一个有价值的单轮 tool-output pruning benchmark 和小模型训练方案。它的贡献主要在于 task formulation、数据集和训练目标:把工具输出压缩定义成 query-conditioned verbatim evidence extraction,并证明一个经过监督微调的 2B 小模型可以在高压缩率下保留较高 recall。
但如果要把它作为 coding agent context pruning 的完整方案,还需要进一步验证它在多轮 agent trajectory 中的真实收益。尤其需要看它是否能在 SWE-Bench 这类端到端任务上同时改善 solved rate、rounds、tokens 和 cost,而不仅是在单次 observation 上取得高 recall 和高 compression。
论文图表摘录
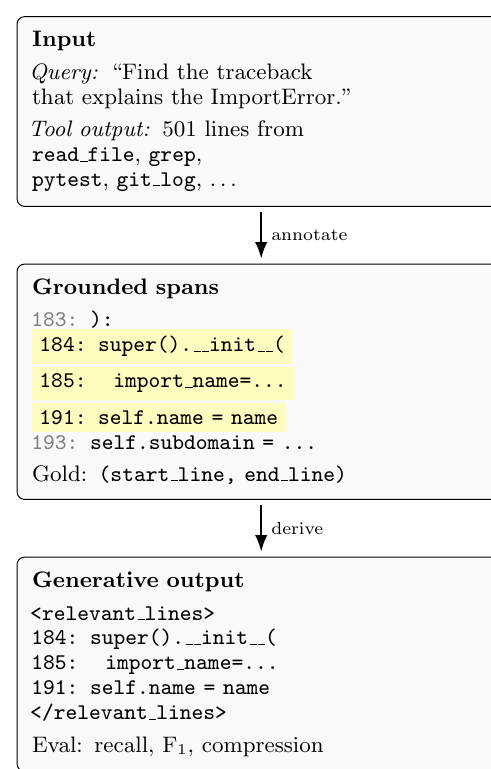
Squeez Figure 1: task-conditioned tool-output pruning 示例
Squeez Table 4: held-out test set 主结果
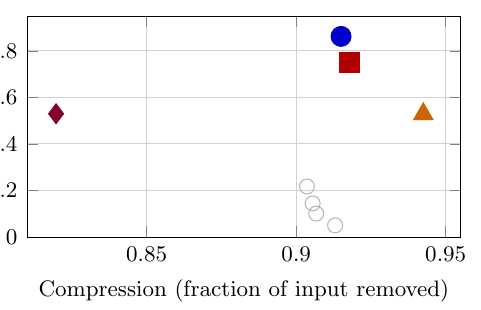
Squeez Figure 2: 输出长度与 recall / F1 关系
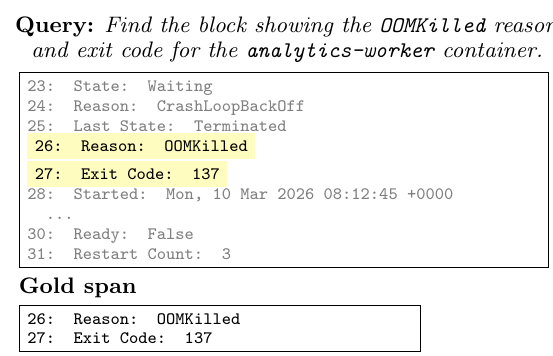
Squeez Figure 3: pruning examples / error modes